AI remembers your conversations.
It forgets your work.AI는 대화를 기억합니다.
정작 일은 잊습니다.
Memory systems are converging fast — but on conversational recall. The units that actually run work — decisions, risks, open questions, who-owns-what — have been first-class in human practice for fifty years, and are absent from state-of-the-art AI memory. This is a field guide to that gap, and why it is the opportunity.
메모리 시스템은 빠르게 수렴하고 있습니다 — 그런데 수렴하는 방향이 '대화 회상'입니다. 정작 일을 굴러가게 하는 단위 — 결정, 리스크, 미해결 질문, 누가 무엇을 책임지는가 — 는 사람이 일하는 방식에서 오십 년 넘게 1급 시민이었지만, 최신 AI 메모리에는 빠져 있습니다. 이 리포트는 그 간극을 짚고, 왜 그것이 기회인지 설명합니다.
An agent can recall your coffee order. It can't tell you why v2 was killed.에이전트는 커피 주문은 기억합니다. v2가 왜 폐기됐는지는 답하지 못합니다.
Ask a modern memory layer to remember a user across three hundred chat turns and it will. Ask it who owns the rollback, why the team killed the v2 launch, or what's still unresolved, and it has no answer — because it was never built to hold those things as first-class objects. It holds facts about a person. Work runs on decisions, risks, and open questions.
최신 메모리 레이어에게 300번의 대화 턴에 걸쳐 사용자를 기억하라고 하면 해냅니다. 그러나 롤백을 누가 책임지는지, 팀이 왜 v2 출시를 접었는지, 무엇이 아직 미해결인지 물으면 답이 없습니다 — 그런 것들을 1급 객체로 담도록 만들어진 적이 없기 때문입니다. 메모리가 담는 것은 사람에 관한 사실입니다. 일은 결정과 리스크와 미해결 질문 위에서 굴러갑니다.
Decades before LLMs, human disciplines already named these units and gave them schemas: Architecture Decision Records, RAID logs (risks, assumptions, issues, dependencies), lessons-learned registers, the military After Action Review. Each treats a decision or a risk as a typed, status-lifecycled, durable record. The dominant AI-memory taxonomy names none of them.
LLM이 등장하기 수십 년 전부터, 사람이 일하는 분야들은 이미 이 단위들에 이름을 붙이고 스키마를 부여했습니다. Architecture Decision Record, RAID 로그(리스크·가정·이슈·의존성), lessons-learned 레지스터, 군의 After Action Review. 모두 결정이나 리스크를 타입이 있고 상태가 관리되는 영속 레코드로 다룹니다. 주류 AI 메모리 분류 체계는 그중 어느 것도 이름 붙이지 않습니다.
The problem isn't that AI memory is too short. It's that it has the wrong primitives. We have spent two years making machines remember conversations. Work was never a conversation.
문제는 AI 메모리가 너무 짧다는 것이 아닙니다. 잘못된 프리미티브를 갖고 있다는 것입니다. 우리는 2년 동안 기계가 대화를 기억하게 만들었습니다. 그러나 일은 애초에 대화였던 적이 없습니다.
What "memory" is — and what it isn't'메모리'란 무엇인가 — 그리고 무엇이 아닌가
"Memory" is the most overloaded word in the agent stack. Before comparing systems, separate it from the three things it's constantly confused with. Each is real; none is sufficient alone.
'메모리'는 에이전트 스택에서 가장 과부하된 단어입니다. 시스템을 비교하기 전에, 늘 혼동되는 세 가지와 먼저 구분합니다. 셋 다 실재하지만, 어느 하나도 단독으로는 충분하지 않습니다.
Context window컨텍스트 윈도우
Working memory. Coherent within a session, gone at its end. Bigger windows help, but cost and "context rot" cap them — and they don't persist.
작업 메모리입니다. 한 세션 안에서는 일관되지만, 세션이 끝나면 사라집니다. 윈도우를 키우면 도움이 되지만 비용과 '컨텍스트 부패'가 한계를 긋습니다 — 그리고 지속되지 않습니다.
RAG
Stateless retrieval over a fixed corpus. Re-derives an answer from raw chunks every time. As Karpathy puts it, the model "rediscovers knowledge from scratch on every question."
고정된 코퍼스 위의 무상태 검색입니다. 매번 원본 청크에서 답을 다시 끌어냅니다. 카르파시의 표현으로는, 모델이 "질문할 때마다 지식을 처음부터 다시 발견"합니다.
Fine-tuning파인튜닝
Parametric memory. Durable but expensive, slow to update, and impossible to attribute or selectively forget. Wrong tool for facts that change weekly.
파라메트릭 메모리입니다. 영속적이지만 비싸고, 갱신이 느리며, 출처를 밝히거나 선택적으로 잊는 것이 불가능합니다. 매주 바뀌는 사실에는 맞지 않는 도구입니다.
Memory메모리
A non-parametric store the system writes back to and maintains across sessions — a compounding artifact, not a transient buffer or a one-shot lookup.
시스템이 다시 써넣고 세션을 가로질러 유지하는 비파라메트릭 저장소입니다 — 일회용 버퍼나 단발 조회가 아니라, 복리로 쌓이는 산출물입니다.
The cleanest articulation of the difference comes from Andrej Karpathy's LLM Wiki pattern (April 2026): instead of re-retrieving chunks, the model "incrementally builds and maintains a persistent wiki — a structured, interlinked collection of markdown files… a persistent, compounding artifact." Hold that image — we return to it at the end.
이 차이를 가장 깔끔하게 표현한 것은 안드레이 카르파시의 LLM Wiki 패턴(2026년 4월)입니다. 청크를 다시 검색하는 대신, 모델이 "영속적인 위키를 점진적으로 짓고 유지한다 — 구조화되고 상호 연결된 마크다운 파일의 모음… 복리로 쌓이는 영속적 산출물"이라는 것입니다. 이 이미지를 기억해 두십시오 — 마지막에 다시 돌아옵니다.

A taxonomy of memory메모리의 분류 체계
The literature has largely converged on a vocabulary borrowed from cognitive science (CoALA, 2024). Two questions: what kind of memory, and along which dimensions it varies. This is the map the rest of the report places systems onto.
학계는 인지과학에서 빌려온 어휘로 대체로 수렴했습니다(CoALA, 2024). 질문은 둘입니다. 어떤 종류의 메모리인가, 그리고 어떤 차원을 따라 달라지는가. 이 리포트의 나머지는 시스템을 바로 이 지도 위에 올려놓습니다.
Types — what kind of memory유형 — 메모리의 종류
Short-term단기
The live context window for the current task. The scratchpad.
현재 작업을 위한 실시간 컨텍스트 윈도우. 메모장.
What happened무슨 일이 있었나
Instance-specific, timestamped events and conversations. The memory stream.
개별 사례 단위의, 타임스탬프가 찍힌 사건과 대화. 메모리 스트림.
What's true무엇이 참인가
Abstracted facts and entities, distilled from episodes. Where "user profile" actually lives.
일화에서 증류된 추상화된 사실과 엔티티. '사용자 프로필'이 실제로 사는 곳.
How to do it하는 방법
Reusable skills and routines — Voyager's executable skill library is the archetype.
재사용 가능한 기술과 루틴 — Voyager의 실행형 스킬 라이브러리가 원형입니다.
The operations연산
Every system is a write → manage → read loop: encode, then consolidate / resolve-contradiction / forget, then retrieve. "Manage" is where quality lives — and where the field is least mature.
모든 시스템은 쓰기 → 관리 → 읽기 루프입니다. 인코딩하고, 통합·모순 해소·망각하고, 검색합니다. 품질은 '관리'에 있습니다 — 그리고 이 분야가 가장 미성숙한 지점이기도 합니다.
Dimensions — how memory systems vary차원 — 메모리 시스템이 갈리는 축
- Storage substrate — vector · knowledge-graph · relational · document · hybrid.저장 기반 — 벡터 · 지식 그래프 · 관계형 · 문서 · 하이브리드.
- Formation (write path) — extraction, summarization, reflection, consolidation, deduplication.형성(쓰기 경로) — 추출, 요약, 성찰, 통합, 중복 제거.
- Retrieval (read path) — similarity, graph traversal, recency·importance·relevance scoring (Generative Agents).검색(읽기 경로) — 유사도, 그래프 순회, 최신성·중요도·관련성 점수(Generative Agents).
- Temporal modeling — static snapshot vs bi-temporal validity (when a fact became true, when it stopped). The rare differentiator.시간 모델링 — 정적 스냅샷 대 양시간(bi-temporal) 유효성(사실이 언제 참이 됐고 언제 멈췄는가). 보기 드문 차별점.
- Scope — single-agent · single-user · multi-user · org.범위 — 단일 에이전트 · 단일 사용자 · 다중 사용자 · 조직.
- Source breadth — conversation-only vs heterogeneous work data (docs, chats, files, connectors).소스 폭 — 대화 전용 대 이종 업무 데이터(문서, 채팅, 파일, 커넥터).
- Governance — who decides what to write, supersede, and forget; the control policy. The newest surveys put this at the center.거버넌스 — 무엇을 쓰고, 대체하고, 잊을지 누가 결정하는가; 통제 정책. 최신 서베이는 거버넌스를 중심에 놓습니다.
Note on "profile" memory: a stable model of a person or org is a product convenience, not a separate cognitive type — academically it's a slice of semantic memory.'프로필' 메모리에 관한 주석: 사람이나 조직의 안정적 모델은 제품상의 편의이지 별도의 인지 유형이 아닙니다 — 학술적으로는 의미 메모리의 한 조각입니다.
Five camps, one map다섯 진영, 하나의 지도
The landscape isn't a list of eighteen products — it's five bets on what memory is for. Placing each system on the taxonomy reveals which problem it actually solves.
이 지형은 18개 제품의 목록이 아닙니다 — 메모리가 무엇을 위한 것인가에 대한 다섯 가지 베팅입니다. 각 시스템을 분류 체계 위에 올려놓으면, 그것이 실제로 푸는 문제가 드러납니다.
Remember the user사용자를 기억한다
Mem0 · Letta (MemGPT) · Honcho · LangMem · Hindsight. Extract facts from chat turns; recall them later. Mostly vector or relational stores. The crowded center of the market — and the part model-native memory is commoditizing fastest.
Mem0 · Letta(MemGPT) · Honcho · LangMem · Hindsight. 대화 턴에서 사실을 추출하고 나중에 회상합니다. 대부분 벡터 또는 관계형 저장소. 시장의 붐비는 중심 — 그리고 모델 내장 메모리가 가장 빠르게 범용화하는 영역.
Model the relations관계를 모델링한다
Zep + Graphiti · Cognee · HippoRAG. Turn input into an entity/edge graph. Zep's Graphiti is the one verified bi-temporal system in the set — facts are invalidated, not deleted, so you can ask "what was true last quarter."
Zep + Graphiti · Cognee · HippoRAG. 입력을 엔티티/엣지 그래프로 바꿉니다. Zep의 Graphiti는 이 집합에서 유일하게 검증된 양시간 시스템입니다 — 사실은 삭제되지 않고 무효화되므로, "지난 분기에 무엇이 참이었나"를 물을 수 있습니다.
Index the corpus코퍼스를 색인한다
Onyx (ex-Danswer) · Glean · Supermemory · R2R · Morphik. Permission-aware search and RAG over Slack, Drive, Gmail, Confluence. Onyx (40+ connectors, open) and Glean (100+, closed) lead. They ingest everything — and flatten it to chunks.
Onyx(구 Danswer) · Glean · Supermemory · R2R · Morphik. Slack·Drive·Gmail·Confluence 위에서 권한을 인식하는 검색과 RAG. Onyx(커넥터 40개+, 오픈)와 Glean(100개+, 클로즈드)이 선두. 모든 것을 수집합니다 — 그리고 청크로 납작하게 만듭니다.
Built into the assistant어시스턴트에 내장
ChatGPT memory + apps-sync · Claude memory / Projects / API tool · Gemini · NotebookLM. The baseline a standalone layer competes against. Converging on managed profile + opt-in connectors — which eats the consumer case.
ChatGPT 메모리 + 앱 싱크 · Claude 메모리 / 프로젝트 / API 도구 · Gemini · NotebookLM. 독립 레이어가 맞서 싸우는 기준선. 관리형 프로필 + 옵트인 커넥터로 수렴 중 — 이것이 소비자 영역을 잠식합니다.
Files the agent maintains에이전트가 유지하는 파일
Karpathy's LLM Wiki · CLAUDE.md / AGENTS.md · plain markdown + git. No product — the agent reads and writes structured files. The practitioner default, and quietly the most schema-honest of all.
카르파시의 LLM Wiki · CLAUDE.md / AGENTS.md · 순수 마크다운 + git. 제품이 아닙니다 — 에이전트가 구조화된 파일을 읽고 씁니다. 현장의 기본값이자, 조용히 가장 스키마에 충실한 방식.
"Some are search systems with a better story""어떤 건 그럴듯한 서사를 입힌 검색이다"
Across all five camps, one practitioner line keeps recurring: everyone says "memory," and they do not mean the same thing. Half the category is retrieval wearing a memory costume. The map is how you tell them apart.
다섯 진영 전체에서 현장의 한 문장이 반복됩니다. 모두가 "메모리"라고 말하지만, 같은 것을 뜻하지 않는다. 이 범주의 절반은 메모리 분장을 한 검색입니다. 이 지도가 둘을 가려내는 방법입니다.
Hindsight (Vectorize, open-sourced December 2025) is the most structured system in the conversation camp — and the clearest sign of where it's heading. Instead of storing flat facts, it runs a Retain → Recall → Reflect loop that builds a temporal entity graph across three networks — world facts, agent experiences, and evolving "mental models" — then reflects over them to revise beliefs. It reports 91.4% on LongMemEval (claiming to be first past 90%) and ~89.6% on LoCoMo — vendor-reported, like every number in §04. The tell: Camp 1's frontier is drifting toward the graph-and-reflection structure of Camp 2, not away from it.
Hindsight(Vectorize, 2025년 12월 오픈소스)는 대화 진영에서 가장 구조화된 시스템이자, 이 진영이 어디로 향하는지 가장 분명히 보여주는 신호입니다. 납작한 사실을 저장하는 대신 Retain → Recall → Reflect 루프로 시간 엔티티 그래프를 짓습니다 — 세계 사실, 에이전트 경험, 진화하는 '멘탈 모델'이라는 세 네트워크에 걸쳐 — 그 위에서 성찰하며 신념을 수정합니다. LongMemEval 91.4%(90% 돌파 최초라고 주장), LoCoMo 약 89.6%를 보고합니다 — §04의 모든 수치처럼 벤더 자가 보고입니다. 신호는 이것입니다. 진영 1의 최전선은 진영 2의 그래프·성찰 구조에서 멀어지는 것이 아니라, 그쪽으로 흐르고 있습니다.
The comparison matrix비교 매트릭스
| System시스템 | Substrate기반 | Temporal시간성 | Source breadth소스 폭 | Scope범위 | Typed records타입 레코드 | License라이선스 |
|---|---|---|---|---|---|---|
| Mem0conversation대화 | Vector (+graph variant)벡터(+그래프 변형) | None없음 | Chat-first; no connectors대화 우선; 커넥터 없음 | Per-user사용자별 | No없음 | Apache-2.0 |
| LettaMemGPT lineageMemGPT 계보 | Postgres + pgvector | None없음 | Files via FilesystemFilesystem로 파일 | Multi-agent다중 에이전트 | Free-text blocks자유 텍스트 블록 | Apache-2.0 |
| Honchotheory-of-mind마음 이론 | Postgres + pgvector | None없음 | Models people, not corpora코퍼스 아닌 사람을 모델링 | Peer / workspace피어 / 워크스페이스 | No없음 | AGPL-3.0 |
| HindsightVectorize · reflectionVectorize · 성찰 | Temporal entity graph시간 엔티티 그래프 | Temporal-aware시간 인식 | Conversation streams대화 스트림 | Per-agent에이전트별 | World / experience / belief nets월드 / 경험 / 신념 네트워크 | MIT |
| Zep + Graphititemporal KG시간 KG | Knowledge graph (Neo4j)지식 그래프(Neo4j) | Bi-temporal양시간 | Episodes; Cloud adds adapters에피소드; Cloud는 어댑터 | Org (Cloud)조직(Cloud) | Custom entity + edge types커스텀 엔티티+엣지 타입 | Apache-2.0 |
| CogneeECL pipelineECL 파이프라인 | Graph + vector + relational그래프 + 벡터 + 관계형 | Event-timestamps이벤트 타임스탬프 | Slack/Notion/Drive (Cloud)Slack/Notion/Drive(Cloud) | Multi-tenant멀티테넌트 | Entities via ontology온톨로지로 엔티티 | Apache-2.0 |
| Onyxenterprise search엔터프라이즈 검색 | Hybrid vector + keyword하이브리드 벡터+키워드 | None없음 | 40+ permission-aware connectors권한 인식 커넥터 40+ | Org조직 | Chunks only청크만 | MIT (CE) |
| Gleanincumbent기존 강자 | Enterprise knowledge graph엔터프라이즈 지식 그래프 | Recency only최신성만 | 100+ connectors, closed커넥터 100+, 클로즈드 | Enterprise엔터프라이즈 | No없음 | Closed클로즈드 |
| Model-nativeChatGPT / Claude / GeminiChatGPT / Claude / Gemini | Proprietary독점 | None public공개된 것 없음 | Opt-in app connectors옵트인 앱 커넥터 | Personal → org개인 → 조직 | No없음 | Closed클로즈드 |
| DIY filesLLM Wiki / CLAUDE.mdLLM Wiki / CLAUDE.md | Markdown + git마크다운 + git | Whatever you write쓰는 만큼 | Anything on disk디스크의 무엇이든 | Whatever you scope정하는 만큼 | Prose, not enforced산문, 강제 안 됨 | — |
green strong · amber partial · grey none. Stars, funding, and exact benchmark figures move weekly; this snapshot is 2026-06. Read the next section before trusting any number.초록 강함 · 호박색 부분적 · 회색 없음. 스타·펀딩·정확한 벤치마크 수치는 매주 변합니다; 이 스냅샷은 2026-06 기준. 어떤 수치든 믿기 전에 다음 절을 읽으십시오.
The two axes that actually separate the field이 분야를 실제로 가르는 두 축
Nobody occupies the top-right — high temporal correctness and broad permission-aware ingestion. Zep has the temporal model but you bring your own data; Onyx and Glean have the connectors but flatten time to "most recent." That empty corner is the structural opening.오른쪽 위는 아무도 차지하지 않았습니다 — 높은 시간 정확성과 넓은 권한 인식 수집을 동시에. Zep은 시간 모델은 있지만 데이터는 직접 가져와야 하고; Onyx와 Glean은 커넥터는 있지만 시간을 "가장 최근"으로 납작하게 만듭니다. 그 빈 코너가 구조적 빈틈입니다.
The same system scored 58%, 66%, and 75% — depending on who ran it같은 시스템이 58%, 66%, 75%를 받았습니다 — 누가 돌렸느냐에 따라
Before the matrix means anything, you need to distrust the leaderboards. In 2025 two leading vendors benchmarked each other on LOCOMO, the standard long-term-conversation test. The numbers tell a cautionary tale about every "we beat everyone" claim.
매트릭스가 의미를 갖기 전에, 먼저 리더보드를 의심해야 합니다. 2025년 두 선두 벤더가 표준 장기 대화 테스트 LOCOMO에서 서로를 벤치마크했습니다. 그 수치들은 "우리가 모두를 이겼다"는 모든 주장에 대한 경고담입니다.
One benchmark, one system, a seventeen-point swing — driven entirely by methodology: which question categories count in the denominator, whose prompt template, single run vs ten-run average, and whether each side configured the other's system correctly. Then an independent audit (Penfield Labs, 2026) found 6.4% of LOCOMO's answer key is wrong, and its automated judge accepted 63% of deliberately-wrong-but-topical answers. Gaps of a few points sit inside the benchmark's own noise.
하나의 벤치마크, 하나의 시스템, 17점의 출렁임 — 전적으로 방법론이 만든 것입니다. 어떤 질문 카테고리를 분모에 넣는가, 누구의 프롬프트 템플릿인가, 단일 실행인가 10회 평균인가, 그리고 각 진영이 상대의 시스템을 제대로 설정했는가. 이어 독립 감사(Penfield Labs, 2026)는 LOCOMO 정답 키의 6.4%가 틀렸고, 자동 채점기가 "의도적으로 틀렸지만 주제는 맞는" 답의 63%를 통과시켰음을 밝혔습니다. 몇 점 차이는 벤치마크 자체의 잡음 안에 들어 있습니다.
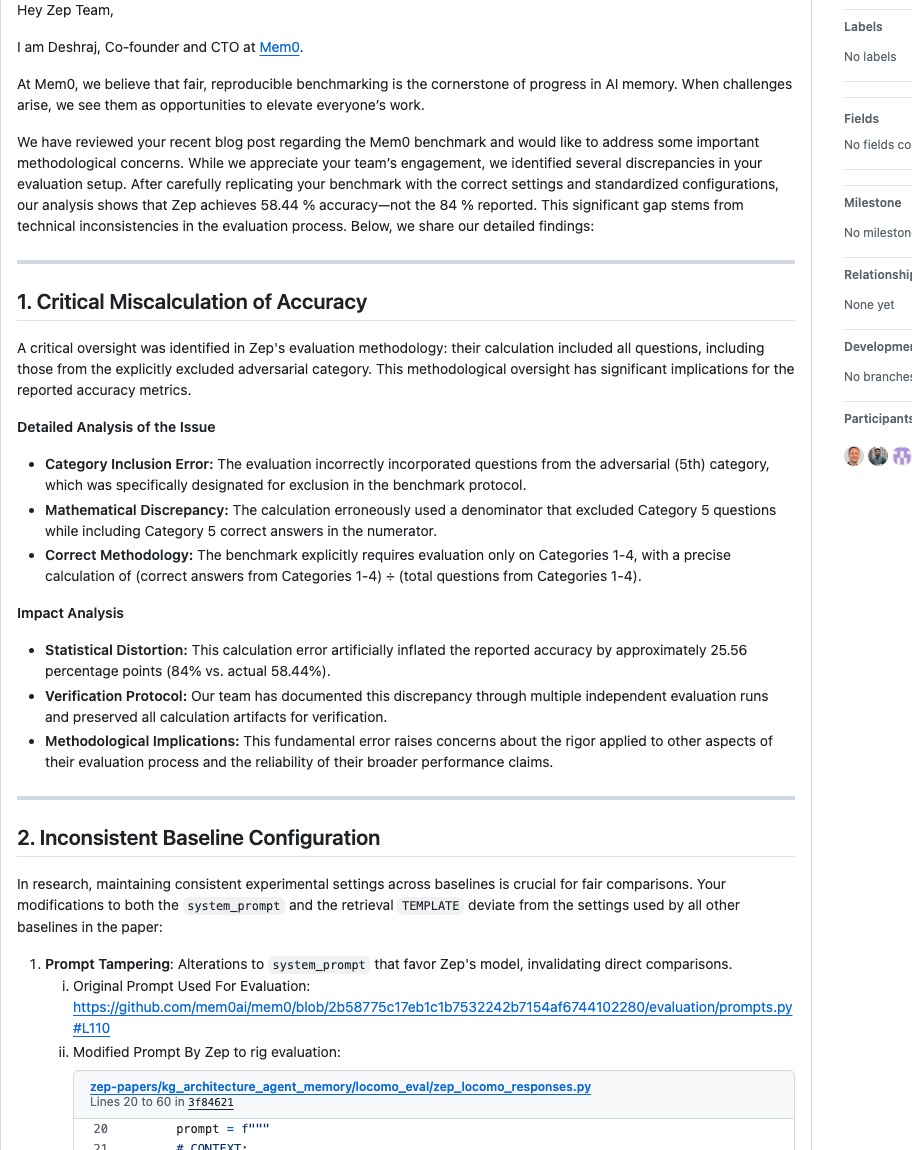
Treat any single-vendor leaderboard claim as marketing. Weight peer-reviewed and independently reproducible results over self-reported percentages — and notice that DMR, the older benchmark, is so saturated that a plain full-context model beats MemGPT on it. The benchmarks measure storage and retrieval. They do not measure the thing that actually differentiates these systems: the formation pipeline.
단일 벤더의 리더보드 주장은 마케팅으로 취급하십시오. 자가 보고 수치보다 동료 심사를 거쳤고 독립적으로 재현 가능한 결과에 무게를 두십시오 — 그리고 더 오래된 벤치마크 DMR은 너무 포화되어, 평범한 풀컨텍스트 모델이 MemGPT를 이깁니다. 벤치마크는 저장과 검색을 측정합니다. 이 시스템들을 실제로 가르는 것 — 형성 파이프라인 — 은 측정하지 않습니다.
What work actually needs to remember일이 실제로 기억해야 하는 것
Flip the question. Forget what the systems store; ask what an agent driving real work must recall. The units aren't "facts about a user." They're the things that run a project — and they fall into four layers.
질문을 뒤집습니다. 시스템이 무엇을 저장하는지는 잊고, 실제 업무를 끌어가는 에이전트가 무엇을 회상해야 하는지 묻습니다. 그 단위는 "사용자에 관한 사실"이 아닙니다. 프로젝트를 굴러가게 하는 것들이고 — 네 개의 층으로 나뉩니다.
The standing picture현재 그림
Project status & health · goals and success criteria · stakeholders (who owns, knows, decides) · artifacts and their current versions · dependencies · milestones.
프로젝트 상태와 건전성 · 목표와 성공 기준 · 이해관계자(누가 책임지고, 알고, 결정하는가) · 산출물과 현재 버전 · 의존성 · 마일스톤.
The record of moves움직임의 기록
Decisions — what, why, which alternatives, who, when · status transitions · commitments and action items (who owes what, by when).
결정 — 무엇을, 왜, 어떤 대안 중에서, 누가, 언제 · 상태 전이 · 약속과 액션 아이템(누가 무엇을, 언제까지).
The hard-won힘들게 얻은 것
Learnings and insights · risks (likelihood, impact, mitigation, status) · open questions · the rationale behind decisions · conventions.
배움과 통찰 · 리스크(가능성, 영향, 완화, 상태) · 미해결 질문 · 결정의 근거 · 관행.
The wiring배선
Who decided what · what blocks what · what supersedes what · and provenance — where each fact came from, so a claim can be trusted or revoked.
누가 무엇을 결정했나 · 무엇이 무엇을 막나 · 무엇이 무엇을 대체하나 · 그리고 출처 — 각 사실이 어디서 왔는가, 그래야 주장을 신뢰하거나 철회할 수 있습니다.
The jobs an agent needs memory to do에이전트가 메모리에 시키는 일
- "Catch me up on project X." — state synthesis"프로젝트 X, 상황 정리해 줘." — 상태 종합
- "What did we decide about Y, and why?" — decision recall with rationale"Y에 대해 우리가 뭘 결정했고, 왜였지?" — 근거가 딸린 결정 회상
- "What's blocking the launch?" — risk and dependency surfacing"출시를 막는 게 뭐지?" — 리스크와 의존성 노출
- "Who do I ask about Z?" — expertise routing"Z는 누구한테 물어봐야 하지?" — 전문성 라우팅
- "What's still open?" · "Don't repeat this mistake." · "What changed since I last looked?""아직 열려 있는 건?" · "이 실수는 반복하지 마." · "내가 마지막으로 본 뒤로 뭐가 바뀌었지?"
- "Onboard a new agent to this work." — the context handoff every multi-session agent fails today"새 에이전트를 이 업무에 합류시켜." — 오늘날 모든 멀티세션 에이전트가 실패하는 컨텍스트 인수인계
Human practice names every one사람의 일하는 방식은 하나하나 이름 붙입니다
- Decisions → Architecture Decision Records — Title, Context, Decision, Status, Consequences (Nygard, 2011; "Adopt" on the ThoughtWorks radar since 2017)결정 → Architecture Decision Record — Title, Context, Decision, Status, Consequences (Nygard, 2011; 2017년부터 ThoughtWorks 레이더 "Adopt")
- Risks & issues → RAID logs, a standard PM register리스크 & 이슈 → RAID 로그, 표준 PM 레지스터
- Learnings → PMBOK lessons-learned register · the military After Action Review배움 → PMBOK lessons-learned 레지스터 · 군의 After Action Review
- All of it: typed, status-lifecycled, durable, version-controlled전부: 타입이 있고, 상태가 관리되고, 영속적이며, 버전 관리됨
SOTA AI memory names none최신 AI 메모리는 하나도 이름 붙이지 않습니다
- LangMem's taxonomy: semantic / episodic / procedural — no decision, risk, or open-question typeLangMem의 분류: 의미 / 일화 / 절차 — 결정·리스크·미해결 질문 타입은 없음
- Letta's shipped blocks: persona + human — chat-companion stateLetta가 제공하는 블록: persona + human — 대화 동반자 상태
- Anthropic's memory tool: a generic file store — a bucket, not a schemaAnthropic의 메모리 도구: 범용 파일 저장소 — 스키마가 아니라 양동이
- Decisions, risks, commitments: hand-rolled, if at all결정·리스크·약속: 있다 해도 직접 만들어야 함
This is the asymmetry the whole report turns on. The mechanism is already blessed — Anthropic tells agents to keep a NOTES.md, Karpathy's LLM Wiki has the model maintain markdown, every coding agent reads a CLAUDE.md. But all of it is freeform prose. The primitives mature human practice proves are first-class have never been built into the memory.
이 비대칭이 이 리포트 전체가 도는 축입니다. 메커니즘은 이미 인정받았습니다 — Anthropic은 에이전트에게 NOTES.md를 유지하라 하고, 카르파시의 LLM Wiki는 모델이 마크다운을 관리하게 하며, 모든 코딩 에이전트는 CLAUDE.md를 읽습니다. 그러나 전부 자유 형식의 산문입니다. 성숙한 사람의 일하는 방식이 1급이라 증명한 그 프리미티브가, 메모리에 들어간 적은 한 번도 없습니다.
Where memory fails work메모리가 일에서 실패하는 지점
Now collide the two spines. Take each work primitive and ask, of each camp: can it capture it, type it, keep it current, and attribute it? The grid is mostly empty — and where it isn't tells you exactly what to build.
이제 두 축을 충돌시킵니다. 각 업무 프리미티브를 두고 각 진영에 묻습니다. 담을 수 있는가, 타입을 줄 수 있는가, 최신으로 유지하는가, 출처를 밝히는가? 격자는 대체로 비어 있고 — 비어 있지 않은 곳이 무엇을 지어야 하는지 정확히 알려줍니다.
| Conversation memory대화 메모리 |
KG · temporal (Zep)KG · 시간 (Zep) |
Work-data RAG업무 데이터 RAG |
Model-native모델 내장 | DIY filesDIY 파일 | |
|---|---|---|---|---|---|
| Decisionswith rationale, supersedable결정근거 포함, 대체 가능 | Extracted as a flat fact; no "why," no status납작한 사실로 추출; '왜'도 상태도 없음 | Expressible as a typed edge — but not shipped타입 엣지로 표현 가능 — 미제공 | Flattened into a document chunk문서 청크로 납작해짐 | Not modeled모델링 안 됨 | Captured as prose; not enforced산문으로 기록; 강제 안 됨 |
| Riskslikelihood · impact · status리스크가능성 · 영향 · 상태 | No risk type리스크 타입 없음 | Buildable, unshipped구축 가능, 미제공 | Only if a doc mentions it문서가 언급할 때만 | No없음 | A RAID.md, if you write oneRAID.md, 직접 쓴다면 |
| Open questionstracked until resolved미해결 질문해소될 때까지 추적 | No없음 | No native type기본 타입 없음 | No없음 | No없음 | Manual수동 |
| Keep-currentsupersede / invalidate / forget최신 유지대체 · 무효화 · 망각 | Append-mostly; stale facts linger대부분 추가만; 낡은 사실이 남음 | Bi-temporal — the one real strength양시간 — 유일한 진짜 강점 | Re-index for freshness최신성 위해 재색인 | Opaque불투명 | Git history, by handGit 히스토리, 수동으로 |
| Provenance + permissionssource-attributed, access-aware출처 + 권한출처 표기, 접근 인식 | Rarely tracked거의 추적 안 됨 | Source on edges; no ACLs엣지에 출처; ACL 없음 | Permission-aware retrieval권한 인식 검색 | Per-account only계정 단위만 | Whatever git gives yougit이 주는 만큼 |
The pattern is consistent across the grid. Conversation-memory captures an episodic fact but can't type a decision or attach its rationale — a decision arrives as "the team chose Postgres," stripped of the alternatives and the why. Work-data RAG ingests the whole corpus but flattens a decision into a chunk of a document; you can retrieve the paragraph, but not the decision-as-object you can supersede. Temporal graphs come closest: Zep's bi-temporal model is the only shipped mechanism that can mark a fact as no-longer-true — but it still models facts, not decisions-with-rationale or risks-with-status.
패턴은 격자 전체에서 일관됩니다. 대화 메모리는 일화적 사실은 담지만 결정에 타입을 주거나 근거를 붙이지 못합니다 — 결정은 "팀이 Postgres를 골랐다"로 도착하고, 대안과 이유는 벗겨져 나갑니다. 업무 데이터 RAG는 코퍼스 전체를 수집하지만 결정을 문서의 청크로 납작하게 만듭니다; 문단은 검색할 수 있어도, 대체할 수 있는 '객체로서의 결정'은 가져올 수 없습니다. 시간 그래프가 가장 근접합니다. Zep의 양시간 모델은 사실을 '더 이상 참이 아님'으로 표시할 수 있는 유일하게 제공되는 메커니즘입니다 — 그러나 여전히 사실을 모델링할 뿐, 근거가 딸린 결정이나 상태가 딸린 리스크는 아닙니다.
And the two genuine strengths never co-occur. Onyx and Glean enforce permissions but have no temporal model; Zep has the temporal model but no permission-aware connectors. Provenance, typing, freshness, and access control each exist somewhere — never together, never on a typed work record.
두 개의 진짜 강점은 결코 함께 나타나지 않습니다. Onyx와 Glean은 권한을 강제하지만 시간 모델이 없고; Zep은 시간 모델은 있지만 권한 인식 커넥터가 없습니다. 출처·타입·최신성·접근 통제는 각각 어딘가에 존재합니다 — 함께인 적은 없고, 타입 있는 업무 레코드 위에 있은 적도 없습니다.
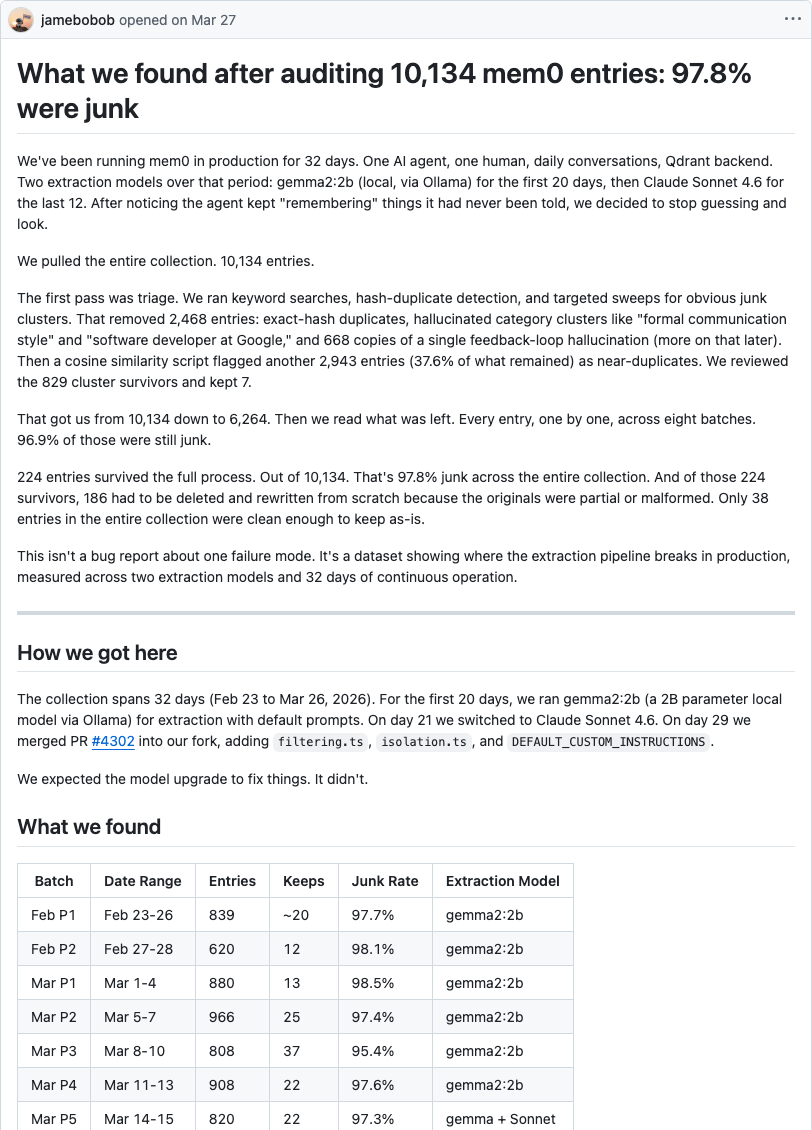
The deepest reason is visible in the field's loudest complaint. Almost every system puts an LLM in the write path — two to three model calls to store a single memory. Practitioners report it as cost (thousand-dollar monthly bills) and as rot: one audited Mem0 deployment found 97.8% of stored memories were junk — a hallucinated user named "John Doe," eight hundred-plus entries insisting "User prefers Vim" when nobody did, secrets leaked into the vector store. Extraction without a schema to extract into produces confident noise.
가장 깊은 이유는 이 분야에서 가장 큰 불만에 드러납니다. 거의 모든 시스템이 쓰기 경로에 LLM을 둡니다 — 메모리 하나를 저장하는 데 모델 호출 두세 번. 현장은 이를 비용(월 수천 달러 청구서)으로, 그리고 부패로 보고합니다. 감사를 받은 한 Mem0 배포에서는 저장된 메모리의 97.8%가 쓰레기였습니다 — 환각으로 만들어낸 "John Doe"라는 사용자, 아무도 그렇지 않은데 "User prefers Vim"을 우기는 800개가 넘는 항목, 벡터 저장소로 새어 든 시크릿. 담을 스키마가 없는 추출은 확신에 찬 잡음을 만듭니다.
Every ingredient already exists in isolation — bi-temporal validity (Zep), custom entity-and-edge types (Graphiti), permission-aware connectors (Onyx, Glean), the agent-maintains-files mechanism (Karpathy, CLAUDE.md). None are combined. The unbuilt system is a small set of typed, status-lifecycled, provenance-bearing work primitives — decision, risk, open-question, commitment — sitting on a bi-temporal graph, fed by permission-aware multi-source connectors. The gap is specific, and it is buildable.
모든 재료가 이미 따로따로는 존재합니다 — 양시간 유효성(Zep), 커스텀 엔티티·엣지 타입(Graphiti), 권한 인식 커넥터(Onyx, Glean), 에이전트가 파일을 유지하는 메커니즘(카르파시, CLAUDE.md). 결합된 것이 없을 뿐입니다. 아직 지어지지 않은 시스템은 타입이 있고, 상태가 관리되며, 출처를 지닌 작은 업무 프리미티브 묶음 — 결정, 리스크, 미해결 질문, 약속 — 이 양시간 그래프 위에 앉아, 권한 인식 다중 소스 커넥터로 공급받는 것입니다. 간극은 구체적이고, 지을 수 있습니다.
Where it's heading어디로 향하는가
Four movements fall out of the survey. The first three are how the field is consolidating. The fourth is the one that isn't being built.
이 서베이에서 네 가지 흐름이 나옵니다. 앞의 셋은 이 분야가 어떻게 굳어지는가입니다. 넷째는 지어지지 않고 있는 것입니다.
Individual, company, agent개인, 회사, 에이전트
The same gap reads three ways, depending on who's holding it.
같은 간극이 쥔 사람에 따라 세 가지로 읽힙니다.
A brain over your own work내 일 위의 브레인
Karpathy's LLM Wiki, lived in. An agent that maintains structured markdown of what you know — and what you've decided — compounding instead of resetting each session.
카르파시의 LLM Wiki를, 실제로 살아내는 것. 내가 아는 것 — 그리고 내가 결정한 것 — 을 구조화된 마크다운으로 유지하는 에이전트. 매 세션 초기화되는 대신 복리로 쌓입니다.
The Company Brain회사의 브레인 (Company Brain)
Permission-aware, temporal, and typed. Not "search over Slack" — a memory that holds the org's decisions, risks, and open questions as records, attributed and supersedable.
권한을 인식하고, 시간을 알고, 타입이 있는 것. "Slack 검색"이 아니라 — 조직의 결정, 리스크, 미해결 질문을 출처가 붙고 대체 가능한 레코드로 쥐고 있는 메모리.
Durable project state영속적인 프로젝트 상태
So each session doesn't re-derive the project from scratch. The handoff problem — "onboard a new agent to this work" — is a memory-schema problem wearing a prompt-engineering costume.
매 세션 프로젝트를 처음부터 다시 도출하지 않도록. 인수인계 문제 — "새 에이전트를 이 업무에 합류시켜" — 는 프롬프트 엔지니어링 분장을 한 메모리 스키마 문제입니다.
The DIY markdown-graph that practitioners keep falling back to — "a memory dir in your git folder; agents can grep it just fine" — isn't a stopgap. It's the schema-first answer the rest of the field is slowly circling back toward. The missing step isn't a bigger model or a better vector index. It's giving that folder the primitives.
현장이 자꾸 되돌아가는 DIY 마크다운 그래프 — "git 폴더 안의 메모리 디렉터리; 에이전트가 grep으로 잘 찾는다" — 는 임시방편이 아닙니다. 나머지 분야가 천천히 되돌아오고 있는, 스키마 우선의 답입니다. 빠진 단계는 더 큰 모델이나 더 좋은 벡터 인덱스가 아닙니다. 그 폴더에 프리미티브를 주는 것입니다.
The field built memory for conversation. Work was waiting for structure.
이 분야는 대화를 위한 메모리를 지었습니다. 일은 구조를 기다리고 있었습니다.